Loading... # 起因 帮同学做的一个爬虫,考前测试题发布于问卷星,每次访问都是不同的试题,因此推测问卷链接的是考试题库,并且问卷星的网页禁止选中文本复制,把题库抓下来何乐而不为。 [](https://imgtu.com/i/oIkPL8) ## 过程 首先爬虫首先考虑使用Python,问卷星作为一个著名的问卷调查平台,肯定有前辈写过相关用来爬问卷星调查问卷的代码。 下面是参考案例: <div class="list-group list-group-lg list-group-sp row" style="margin: 0"><div class="col-sm-6"> <a href="https://blog.csdn.net/wozaiyizhideng/article/details/106485259" target="_blank" class="no-external-link no-underline-link list-group-item no-borders box-shadow-wrap-lg"> <span class="pull-left thumb-sm avatar m-r"> <img noGallery src="https://banwuyan.cc/usr/plugins/Handsome/assets/image/nopic.jpg" alt="Error" class="img-square"></span> <span class="clear"><span class="text-ellipsis"> Python3 爬虫--- 问卷星内容爬取</span> <small class="text-muted clear text-ellipsis">Python3 爬虫--- 问卷星内容爬取_wozaiyizhideng的博客-CSDN博客_爬虫 问卷星</small> </span> </a> </div></div> 一些区别,给出的案例中,所要爬取的问卷页面是静态的,每次访问问卷内容不会改变,分析页面的源代码也发现,网页元素标签也有所差异,因此不能直接拿过来使用,结合实际情况修改一下,完成自动爬取试题库。 [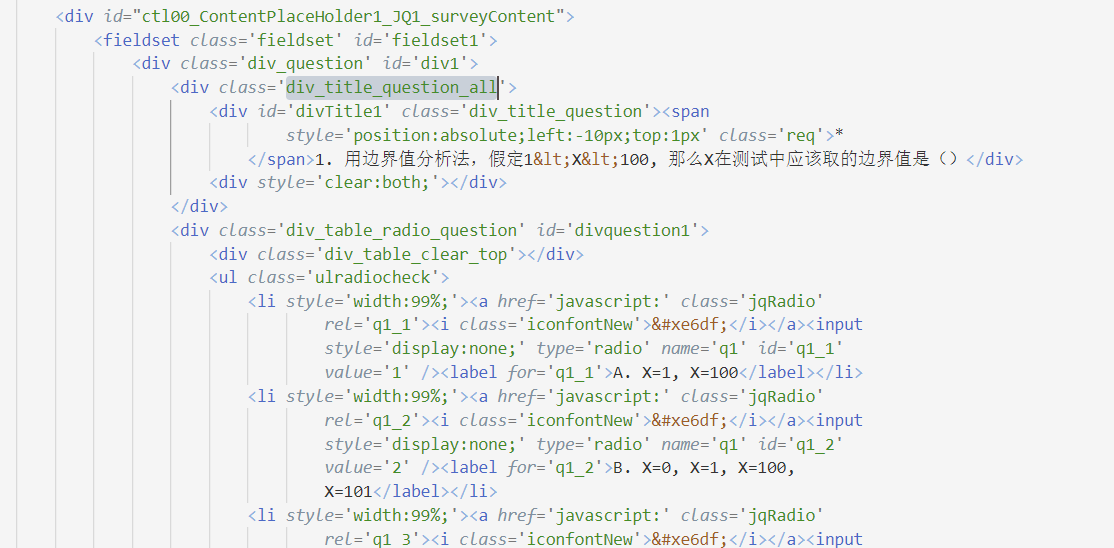](https://imgtu.com/i/oIkkdg) [](https://imgtu.com/i/oIkFeS) 最终代码如下: ``` # coding=gbk import time from requests_html import HTMLSession # wenjuanxing_ID = 55123312 # wenjuanxing_URL = "https://ks.wjx.top/jq/{}.aspx".format(wenjuanxing_ID) wenjuanxing_URL = "https://ks.wjx.top/vm/PpUtjIg.aspx" def parse_post_data(resp,s): ''' 解析问题和选项 ''' questions = resp.html.find('fieldset', first=True).find('.field') for i, q in enumerate(questions): title = q.find('.field-label', first=True).text choices = [t.text for t in q.find('.ui-radio')] print(title) with open(s, 'a', encoding='utf-8') as f: f.write(title + "\n") for choice in choices: print(choice) with open(s, 'a', encoding='utf-8') as f: f.write(choice + "\n") print('***************************************************\n') time.sleep(0.2) with open(s, 'a', encoding='utf-8') as f: f.write('***************************************************\n') def main(): print('开始爬取试卷内容') print('链接:%s' % wenjuanxing_URL) r = int(input("爬取的套数")) r = r + 1 for i in range(1,r): s = "第" + str(i) + "套测试试卷.txt" with open(s, 'a+', encoding='utf-8') as f: f.write('\n试卷' + str(i) + "\n") session = HTMLSession() resp = session.get(wenjuanxing_URL) parse_post_data(resp,s) if __name__ == '__main__': main() ``` ## 结果 [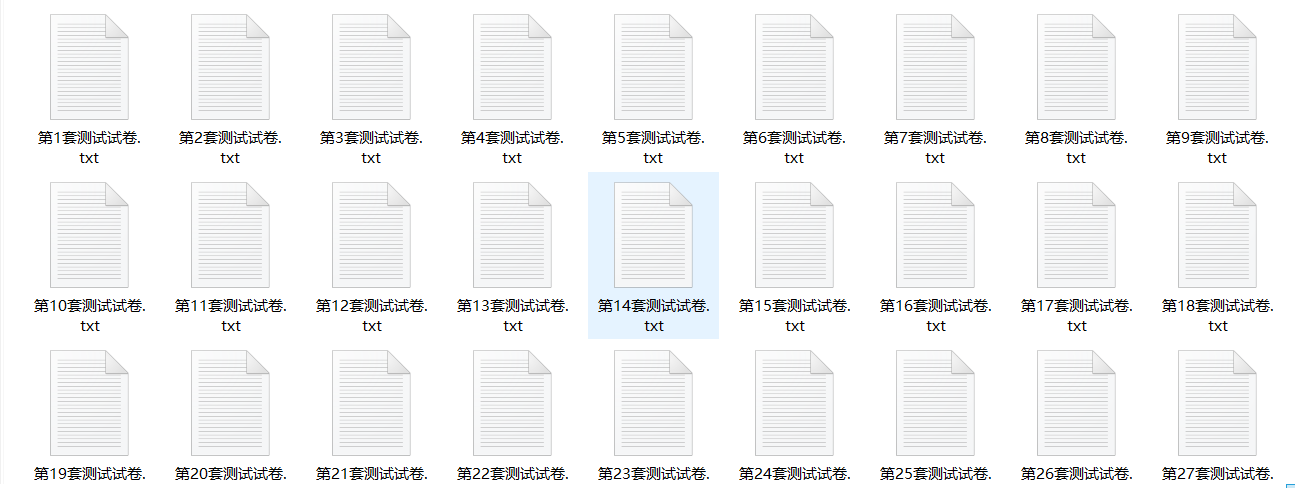](https://imgtu.com/i/oIkCsf) 最后修改:2022 年 02 月 26 日 © 允许规范转载 赞 如果觉得我的文章对你有用,请随意赞赏



